Discriminating between Similar Languages 2015 (Finished)
Discriminating between similar languages and language varieties is one of the bottlenecks of language identification systems. This aspect has been topic of a number of papers published in the last years as well as of the first Discriminating between Similar Languages (DSL) shared task held in 2014.
Results
The tables containing the results are available in this link.
The shared task report can be found here and the bib entry is the following:
@InProceedings{zampieri-EtAl:2015:LT4VarDial1,
author = {Zampieri, Marcos and Tan, Liling and Ljube\v{s}i\'{c}, Nikola and Tiedemann, J\"{o}rg and Nakov, Preslav},
title = {Overview of the DSL Shared Task 2015},
booktitle = {Proceedings of the Joint Workshop on Language Technology for Closely Related Languages, Varieties and Dialects},
month = {September},
year = {2015},
address = {Hissar, Bulgaria},
publisher = {Association for Computational Linguistics},
pages = {1--9}
}
Data
For the DSL shared task 2015 edition, we are releasing two new versions of the DSL corpus collection (DSLCC), the version 2.0 and 2.1. The version 2.0 is the standard shared task training material whereas the version 2.1 can be used for the unshared task track or as additional training material.
This year apart from the similar languages and varieties we are also releasing texts from other languages to emulate a real-world language identification scenario. The two versions who will be release are the following:
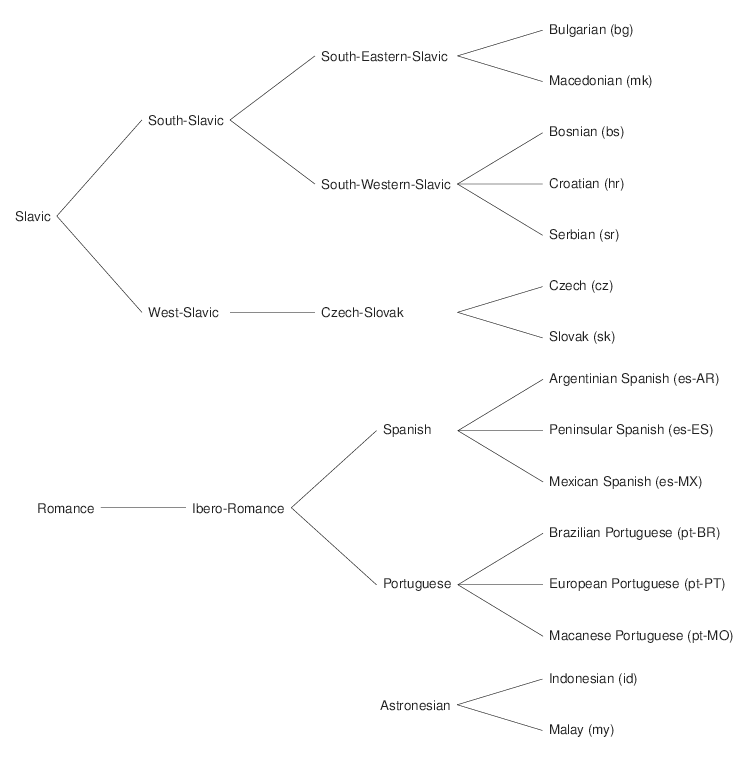
- DSLCC v. 2.0. containing Bulgarian, Macedonian, Serbian, Croatian, Bosnian, Czech, Slovak, Argentinian Spanish, Peninsular Spanish, Brazilian Portuguese, European Portuguese, Malay, Indonesian and a group containing texts written in a set of other languages.
- DSLCC v. 2.1. containing all the DSLCC v. 2.0. plus Mexican Spanish and Macanese Portuguese.
The corpus contains 20,000 instances per language (18,000 training + 2,000 development). Each instance is an excerpt extracted from journalistic texts containing 20 to 100 tokens and tagged with the country of origin of the text. A language tree with all the languages is here.
{kind=link}
The Shared Task
Twenty-five days after the release of the training set (see dates below), two test sets (A and B) will be released. Each of them will contain 1,000 unidentified instances of each language to be classified according to the country of origin.
- Test set A contains original unmodified newspaper texts.
- Test set B contains modified newspapers texts processed with NER taggers to substitute named entities for place holders.
Participants should return their results in up to 2 days after the release of the test sets. Scores will be calculated according to the systems' accuracy in identifying the country of origin of the text. We allow two kinds of submissions (please indicate this when you fill out your registration form):
- Closed submission: Using ONLY the training corpus provided by the DSL shared task (DSLCC v.2.0).
- Open submission: Using ANY corpus for training including or not the DSLCC v.2.0.
Teams are allowed to submit up to six runs to each submission (three for each test set (A and B)).
The best systems will be invited to submit a paper describing their findings (8 pages + 2 for references). Submissions should be formatted according to the RANLP template
The Unshared Task Track
The DSLCC was compiled to serve as a standardise dataset for the discrimination of similar languages and related tasks. For this reason, along with the shared task, this edition we are proposing an unshared task track inspired by the unshared task in PoliInformatics from 2014.
To participate in the unshared task track, teams should use any of the versions of the DSLCC to investigate differences between similar languages and language varieties using NLP methods. The fundamental question is: What are the most important differences between these similar languages and language varieties?
Some questions that should be answered are:
- Are there fundamental differences in grammar between them? What are they?
- What are the most distinctive lexical choices of each similar language?
- Which text representation should be used to investigate variation best?
- What is the impact of both lexical and grammatical variation for NLP applications?
The unshared task track is not a competition but an interesting linguistic exercise. Interested participants should fill out the registration to receive the data and submit their papers until July 20th, 2015. Submissions should be formatted according to the RANLP template. More information here.
Dates
The shared task dates for 2015 are:
- Training set release: May 20th, 2015
- Test set release: June 22th, 2015
- Results submission due: June 24th, 2015
- Results announced: June 26th, 2015
- Paper submission deadline (unshared task):
July 6th, 2015July 20th, 2015 - Paper submission deadline (shared task): July 20th, 2015
- Acceptance notification (shared and unshared): August 1st, 2015
- Camera-ready versions:
August 9th, 2015August 14th, 2015
DSL 2014: In the 2014 edition we provided a training and a test set of 13 different languages organized in 6 groups (more information here). The dataset contained journalistic texts and it is entitled DSL Corpus Collection. For more information, you may wish to take a look at the DSL 2014 Shared Task report and the dataset description paper.